
Keyword extraction is a vital task in the field of text mining, such as spam e-mail classification, abusive language detection, sentiment analysis, and emotion mining. At LDSA, we are working on the development of NLP, graph mining, and deep learning-based keyword extraction techniques to identify (i) domain-specific, and (ii) generic keywords from formal and informal (user-generated noisy content) text documents. Some of our proposed techniques are language-agnostic and they can be used after some tuning to handle texts of different languages.
Read More

The frequent usage of figurative language, such as sarcasm, irony, metaphor, simile, hyperbole, humor, and satire on online social networks, especially on Twitter, has the potential to mislead traditional text information processing (e.g., sentiment analysis, recommendation techniques) systems. Due to the extensive use of slangs, bashes, flames, and non-literal texts, tweets are a great source of figurative language. We have made an in-depth survey of the state-of-the-art techniques for computational detection of the aforesaid seven different figurative language categories, which working of the development of different figurative language detection approaches using rule-based, machine learning, and deep-learning techniques.
Read More

Due to the fast and mass-level dissemination capabilities of the online social network (OSN), adversaries exploit them for various illicit activities. OSN platforms are facing a threat in the form of rumors, where a user either knowingly or unknowingly diffuses false information about an individual, historical facts, etc. The political parties, antisocial elements, and adversaries are exploiting the huge user-base, real-time information diffusion, and lack of effective control mechanism to diffuse rumors on OSN. To this end, we are working towards the development of graph-theoretic embedding-based approach to model user-generated contents for rumor detection.
Read More

Recommender system design is a well-studied problem to deal with the information overload problem. However, most of the existing recommendation approaches suffer from different open challenges like cold-start, data sparsity, limited content, and long tail problems. Context-aware recommender systems have been considered by many researchers to deal with some of these issues. However, non-existence of domain ontology containing contextual information is the major hindrance for the development of such systems. To this end, we have developed a context-aware movie ontology (CAMO) that contains movie concepts, relationships, and various representational and interactional contextual features. Since existing movie databases do not contain all contextual features, we have generated a real-world movie dataset from Linked Open Data (LOD) and movie databases like IMDB and Rotten Tomatoes that contain complete context-based movie profiles.
Read More
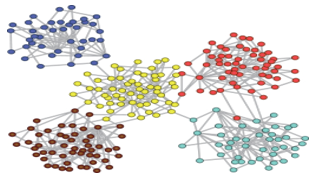
Community detection is an important task for identifying the structure and function of complex networks like online social networks. To this end, we are working on the development of different community mining and analysis methods that are computationally faster, scalable to large-scale networks, and able to find significant community structures in social networks. We have developed OCMiner to identify overlapping community structures in online social networks which uses a novel distance function and automatically determines the neighborhood threshold parameter for each node locally from the underlying network. We have also proposed a unified framework, HOCTracker, for tracking the evolution of hierarchical and overlapping communities in online social networks. Unlike most of the dynamic community detection methods, HOCTracker adapts a preliminary community structure towards dynamic changes in social networks using a novel density-based approach for detecting overlapping community structures, and automatically tracks evolutionary events like birth, growth, contraction, merge, split, and death of communities. Currently, we are working towards exploring the snowball chain formation approach for finding communities in social networks.
Read More
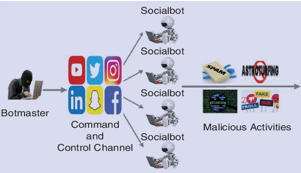
Socialbot is a category of sophisticated and modern threat entities in the form of automated agents that are the native of the social media platforms and responsible for various modern weaponized information-related attacks, such as astroturfing, misinformation diffusion, and spamming. To this end, we have developed an attention-aware deep neural network model, DeepSBD, for detecting socialbots that models users’ behavior using profile, temporal, activity, and content information. It jointly models OSN users’ behavior using Bidirectional Long Short Term Memory (BiLSTM) and Convolutional Neural Network (CNN) architectures.
Read More

The open nature and large user base of online social network are frequently exploited by automated spammers, content polluters, and other ill-intended users to commit various cybercrimes, such as cyberbullying, trolling, rumor dissemination, and stalking. To this end, we have proposed a hybrid approach for detecting automated spammers by amalgamating community-based features with other feature categories, namely metadata-, content-, and interaction-based features. It characterizes users based on their interactions with their followers given that a user can evade features that are related to his/her own activities, but evading those based on the followers is difficult.
Read More

Also known as Affective Computing or Artificial Emotional Intelligence, Emotion AI is one of the emerging areas of Artificial Intelligence that detects and interprets human emotional signals. Data sources could be text (written expressions using emojis), audio (tonality of voice), video (facial movement analysis, gait analysis and physiological signals) or combinations thereof. Emotion AI has started rooting its applications in various areas like advertising, customer service, and healthcare. Our research in this direction mainly focuses on analyzing textual data along with emojis for sentiment analysis and emotions detection.
Read More

Deep learning has wide applications in many data analysis and natural language processing applications. Word representation is a successful application of deep learning that uses the distributional information of words from a sizeable corpus. However, distributional representation of a word is unable to capture distant relational knowledge, representing the relational semantics. To this end, we are working on the development of word representation approach using distributional and relational contexts that augments the distributional representation of a word using the relational semantics extracted as syntactic and semantic association between entities from the underlying corpus. We are also working on the development of attention-based mechanisms to handle the problem of imbalanced textual data problem for improving the accuracy of document classifiers.
Read More

The subgraph isomorphism finding problem is a well-studied problem in the field of computer science and graph theory, and it aims to enumerate all instances of a query graph in the respective data graph. To this end, we have presented an efficient method, SubISO, to find subgraph isomorphisms using an objective function, which exploits some isomorphic invariants and eccentricity of the query graph’s vertices. The proposed objective function is used to determine pivot vertex, which minimizes both number and size of the candidate regions in the data graph. SubISO also limits the maximum recursive calls of the generic SubgraphSearch() function to deal with straggler queries for which most of the existing algorithms show exponential behavior. we have also developed an efficient solver, SubGlw, for subgraph isomorphism finding which first decomposes data graph into small-size candidate subgraphs using a ranking function and then searches the embeddings of the pattern graph in each of them separately. The ranking function is designed in such a way that it minimizes both number and size of the candidate subgraphs.
Read More

The proliferation of online social media is a catalyzing agent for persuasion towards cyber crimes that range from cyber terrorism and drug smuggling to cyber bullying, pornography, and such other heinous acts. User profiling from publicly available data is one of the key tasks towards open source intelligence. However, multiple persons share common name (aka namesakes) and a particular person is known by different names (aka aliases) in different platforms. To this end, we have presented a generic context-based approach for mining alias names of namesakes sharing a common name on the Web. In the recent past, it has been found that the web is also being used as a tool by radical or extremist groups and users to practice several kinds of mischievous acts with concealed agendas and promote ideologies in a sophisticated manner. To this end, we have presented an application of collocation theory to identify radically influential users in web forums. We have also developed a Bilingual Sentiment Analysis Lexicon (BiSAL) to analyze dark web forums for cyber security.
Read More

The extensive use of digital devices by individuals generates a significant amount of private data which creates challenges for investigation agencies to protect suspects’ privacy. We have proposed a privacy-preserving digital forensics (P2DF) framework, which facilitates investigation through maintaining confidentiality of the suspects through various privacy standards and policies. we have also introduced the concept of quaternary privacy levels and their protection mechanism in computer forensics investigation process. The privacy levels are identified on the basis of different entities and their participation roles during a computer forensics investigation process and represent different granule of privacy that can be enforced by the court of law depending on the nature of crime to be investigated. We have also presented a unified social graph-based text mining framework to identify digital evidences from users' chat log data.
Read More

Biomedical and health informatics refer to the field that is concerned with the application of information technology to improve individual health, health care, public health, and biomedical research. To this end, we have done an extensive work in the areas of biomedical entities and relations extractions from biomedical texts, and development of biological relation extraction and query answer from Medline abstracts using ontology-guided text mining. We have also developed a biomedical text analytics system, DiseaSE (Disease Symptom Extraction), to identify and extract disease symptoms and their associations from biomedical text documents retrieved from the PubMed database.
Read More
![]()
![]()